« ImageBot » : différence entre les versions
(Wikipastbot update) |
Aucun résumé des modifications |
||
| Ligne 20 : | Ligne 20 : | ||
== Performances == | == Performances == | ||
*Ce bot étant général il ne précise pas la catégorie du mot que l'on recherche, ainsi pour certains lieux l’ajout d’image n’est pas adéquat. En effet un lieu ayant un nom de personne ou d’autres choses plus populaires aboutira à cette recherche et non celle voulue. Une possible | *Ce bot étant général, il ne précise pas la catégorie du mot que l'on recherche, ainsi pour certains lieux l’ajout d’image n’est pas adéquat. En effet un lieu ayant un nom de personne ou d’autres choses plus populaires aboutira à cette recherche et non celle voulue. Une solution possible pour des recherches manuelles est présentée avec le code IMAGEBOT_v2_namesearch. | ||
*L'implementation du bot [[Listepagesbot]] permettrait d'obtenir la liste de toutes les pages du wiki afin d’ajouter une image à cette liste entière et pas seulement les lieux de naissance et les biographies. Cependant, en référence au point précédent, il faudrait implémenter une précision de la catégorie du mot recherché. Nous ne l'avons pas fait afin de garder le côté général du bot, mais aussi car ceci est difficilement réalisable. En effet il faudrait rechercher des schémas qui permettent d'identifier le type d'entrée (comme par exemple majuscules aux deux mots pour une personne ou une préposition au milieu des trois mots pour un lieu). D'autres options ont | *L'implementation du bot [[Listepagesbot]] permettrait d'obtenir la liste de toutes les pages du wiki, afin d’ajouter une image à cette liste entière et pas seulement les lieux de naissance et les biographies. Cependant, en référence au point précédent, il faudrait implémenter une précision de la catégorie du mot recherché. Nous ne l'avons pas fait afin de garder le côté général du bot, mais aussi car ceci est difficilement réalisable. En effet, il faudrait rechercher des schémas qui permettent d'identifier le type d'entrée (comme par exemple majuscules aux deux mots pour une personne ou une préposition au milieu des trois mots pour un lieu, et là il y aura encore des problèmes avec les noms de nobles, ex: "Lancelot du Lac"). D'autres options ont été présentées lors du cours 8 de Maud Ehrmann. Cependant, le code permets de rajouter une catégorie en spécifiant une page de référence, de laquelle ont aimerait aussi considérer les entrées dans l'extraction du bot, de la même facon que pour les pages de références [[Naissance]] et [[Biographies]] d'où le bot extrait la liste des pages a traiter. En effet, la liste fourni par [[Listepagesbot]] ne précise pas la catégorie de chaque titre et donc il faudrait un autre bot qui s'occuperait de cette fonction. | ||
*Problème si quelqu'un a déjà ajouté manuellement une image auparavant mais qui n'est pas une image de la personne ou du lieu de la page | *Problème si quelqu'un a déjà ajouté manuellement une image auparavant mais qui n'est pas une image de la personne ou du lieu de la page: La première telle image sera alors déplacée au début de la page, comme si c'était une image qui illustrait la page mais qui était mal placée. Les images suivantes ne seraient pas touchés. Le bot n'accèpte donc pas un placement individuel de la première image. | ||
*Le bot ne fonctionne pas si la page à modifier existe, mais est vide. (il vérifie si une image est présente dans un caractère vide et donc affiche une erreur). Cependant, il fonctionne si la page est inexistante et donc dans ce cas il va la créer et placer l'image (il ne vérifie pas la présence ou non d'image car la page n'existait pas et donc le bot fonctionne). Ce problème de page vide peut être réglé avec un contrôle de page vide et une action à réaliser dans ce cas. Ou avec un Bot séparé qui s'occupe | *Le bot ne fonctionne pas si la page à modifier existe, mais est vide. (il vérifie si une image est présente dans un caractère vide et donc affiche une erreur). Cependant, il fonctionne si la page est inexistante et donc, dans ce cas, il va la créer et placer l'image (il ne vérifie pas la présence ou non d'image car la page n'existait pas et donc le bot fonctionne). Ce problème de page vide peut être réglé avec un contrôle de page vide et une action à réaliser dans ce cas. Ou avec un Bot séparé qui s'occupe de supprimer les pages crées mais vides. | ||
== Code == | == Code == | ||
=== IMAGEBOT_v2_categorysearch === | === IMAGEBOT_v2_categorysearch === | ||
Code automatisé pour la recherche des bibliographies et des endroits a | Code automatisé pour la recherche des bibliographies et des endroits a partir des Pages [[Biographies]] et [[Naissance]]. | ||
Des autres Pages de référence peuvent être | Des autres Pages de référence peuvent être ajoutées. | ||
Attention: Une fois lancé ce bot modifie | Attention: Une fois lancé ce bot modifie beaucoup de pages, c'est pourquoi une confirmation des Titres extraits dans les pages est necessaire. Celle-ci peut aussi être enlevée. | ||
<nowiki> | <nowiki> | ||
abcd= contient tous les pages sources pour éxtraire les titres des pages | abcd= contient tous les pages sources pour éxtraire les titres des pages | ||
| Ligne 202 : | Ligne 202 : | ||
=== IMAGEBOT_v2_namesearch === | === IMAGEBOT_v2_namesearch === | ||
Recherche non automatisé qui permet de préciser des paramètres de recherche plus spécialisées comme l'ajout du paramètre "place" pour les endroits. Et qui ajoute un paramètre de décision si on souhaite | Recherche non automatisé qui permet de préciser des paramètres de recherche plus spécialisées comme l'ajout du paramètre "place" pour les endroits. Et qui ajoute un paramètre de décision si on souhaite remplacer une image déjà en ligne. | ||
Ou lancement du Bot pour une seule page en utilisant | Ou lancement du Bot pour une seule page en utilisant | ||
Version du 22 mai 2017 à 19:21
Description
ImageBot scan toutes les pages de biographies, certaines de lieu du wiki et les illustre en y insérant une image en Creative Commons issu de la bibliothèque d’image Yahoo. Lorsque le bot scan une page, il vérifie d’abord si cette page possède une image et s'il n’y a pas d’image il ajoute une image adéquate en haut à droite de la page en question. Si une image est déjà présente sur la page mais qu’elle n’est pas au tout début, alors elle sera déplacée au tout début mais une nouvelle image ne sera pas ajoutée.
Pour ajouter une image aux pages biographiques, le bot scan la page Biographies et pour chaque personne il y ajoute une image selon les règles précédentes.
Pour les lieux, pour le moment, le bot scan les lieux de la page Naissance et pour chaque entrée y ajoute aussi une image.
Pour recevoir une liste de titres de pages on peut facilement insérér une condition dans la recherche des titres afin d'extraire des nouveaux paramêtres de recherche.
Nous avons testé sur une centaine d'entrées et tant que le layout de la page Biographies/Naissance n'est pas modifié par un autre bot il n'y a aucun conflit avec les autres bots. Une période optimale pour le lancement du bot est tout les trois jours.
Exemples
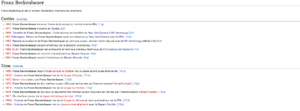
Cette page
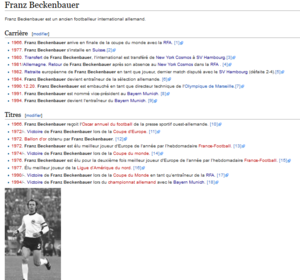
et cette page
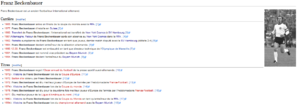
donnent toutes les deux cette page



Performances
- Ce bot étant général, il ne précise pas la catégorie du mot que l'on recherche, ainsi pour certains lieux l’ajout d’image n’est pas adéquat. En effet un lieu ayant un nom de personne ou d’autres choses plus populaires aboutira à cette recherche et non celle voulue. Une solution possible pour des recherches manuelles est présentée avec le code IMAGEBOT_v2_namesearch.
- L'implementation du bot Listepagesbot permettrait d'obtenir la liste de toutes les pages du wiki, afin d’ajouter une image à cette liste entière et pas seulement les lieux de naissance et les biographies. Cependant, en référence au point précédent, il faudrait implémenter une précision de la catégorie du mot recherché. Nous ne l'avons pas fait afin de garder le côté général du bot, mais aussi car ceci est difficilement réalisable. En effet, il faudrait rechercher des schémas qui permettent d'identifier le type d'entrée (comme par exemple majuscules aux deux mots pour une personne ou une préposition au milieu des trois mots pour un lieu, et là il y aura encore des problèmes avec les noms de nobles, ex: "Lancelot du Lac"). D'autres options ont été présentées lors du cours 8 de Maud Ehrmann. Cependant, le code permets de rajouter une catégorie en spécifiant une page de référence, de laquelle ont aimerait aussi considérer les entrées dans l'extraction du bot, de la même facon que pour les pages de références Naissance et Biographies d'où le bot extrait la liste des pages a traiter. En effet, la liste fourni par Listepagesbot ne précise pas la catégorie de chaque titre et donc il faudrait un autre bot qui s'occuperait de cette fonction.
- Problème si quelqu'un a déjà ajouté manuellement une image auparavant mais qui n'est pas une image de la personne ou du lieu de la page: La première telle image sera alors déplacée au début de la page, comme si c'était une image qui illustrait la page mais qui était mal placée. Les images suivantes ne seraient pas touchés. Le bot n'accèpte donc pas un placement individuel de la première image.
- Le bot ne fonctionne pas si la page à modifier existe, mais est vide. (il vérifie si une image est présente dans un caractère vide et donc affiche une erreur). Cependant, il fonctionne si la page est inexistante et donc, dans ce cas, il va la créer et placer l'image (il ne vérifie pas la présence ou non d'image car la page n'existait pas et donc le bot fonctionne). Ce problème de page vide peut être réglé avec un contrôle de page vide et une action à réaliser dans ce cas. Ou avec un Bot séparé qui s'occupe de supprimer les pages crées mais vides.
Code
IMAGEBOT_v2_categorysearch
Code automatisé pour la recherche des bibliographies et des endroits a partir des Pages Biographies et Naissance.
Des autres Pages de référence peuvent être ajoutées.
Attention: Une fois lancé ce bot modifie beaucoup de pages, c'est pourquoi une confirmation des Titres extraits dans les pages est necessaire. Celle-ci peut aussi être enlevée.
abcd= contient tous les pages sources pour éxtraire les titres des pages après la boucle for sur abcd il y a un names=[] qui peut être décommenté et utilisé pour tester le bot sur une seule ou plusieures pages test.
import re
import urllib2
import requests
import os
from bs4 import BeautifulSoup
# -*- coding: utf-8 -*-
user='***'
passw='***'
baseurl='http://wikipast.epfl.ch/wikipast/'
baseur2='https://images.search.yahoo.com/search/images;_ylt=AwrB8plXwf9YqRkAXSWJzbkF?p='
abcd=['Biographies','Naissance']
# Login request
payload={'action':'query',
'format':'json',
'utf8':'',
'meta':'tokens',
'type':'login'}
r1=requests.post(baseurl + 'api.php', data=payload)
#login confirm
login_token=r1.json()['query']['tokens']['logintoken']
payload={'action':'login',
'format':'json',
'utf8':'',
'lgname':user,
'lgpassword':passw,
'lgtoken':login_token}
r2=requests.post(baseurl + 'api.php', data=payload, cookies=r1.cookies)
params3='?format=json&action=query&meta=tokens&continue='
r3=requests.get(baseurl + 'api.php' + params3, cookies=r2.cookies)
edit_token=r3.json()['query']['tokens']['csrftoken']
edit_cookie=r2.cookies.copy()
edit_cookie.update(r3.cookies)
#extract names of biographies
names=[]
for abc in abcd:
result=requests.post(baseurl+'api.php?action=query&titles='+abc+'&export&exportnowrap')
soup=BeautifulSoup(result.text,'html.parser')
resultt=str(soup)
if (abc=='Biographies'):
resulttt=resultt.split("{|")
resultttt=resulttt[1].split("|}")
test=resultttt[0].split("|")
for xx in test:
if (xx.find("]]")!=-1):
xx=xx.split("[[")[1].split("]]")[0]
a=xx.replace(' ','_')
print(a.decode('UTF-8'))
names.append(a.decode('UTF-8'))
if (abc=='Naissance'):
resulttt=resultt.split("*")
test=resulttt[1:len(resulttt)]
for xx in test:
xxx=xx.split("/")[1]
xxx=xxx.split("[[")
if len(xxx)>1:
xxx=xxx[1].split("]]")[0]
xxx=xxx.replace(' ','_')
if(xxx!='Naissance'):
names.append(xxx.decode('UTF-8'))
print(xxx.decode('UTF-8'))
#if you are not sure if your extraction works properly, confirm manually
print('Do you want to modify above pages?\n if yes press button \n if not interrupt! add names to modify un line 73 names=[?] and uncomment\n\n')
os.system("pause")
print('sure?')
os.system("pause")
#If you want to run with single page use:
#names=['Michael_Schumacher']
#recherche images creative common & mise sur le serveur
for name in names:
result=requests.post(baseurl+'api.php?action=query&titles='+name+'&export&exportnowrap')
soup=BeautifulSoup(result.text, 'html.parser')
code=''
for primitive in soup.findAll("text"):
code+=primitive.string
if (code.find("Fichier")==-1):
print('\n****************\n'+'search image for '+name+'\n****************\n')
#attention au codage
result=urllib2.urlopen(baseur2+name.encode('utf-8', 'replace')+'&imgsz=medium&imgty=photo&ei=UTF-8&fr=sfp&imgl=fsu&fr2=p%3As%2Cv%3Ai')
content=result.read().decode('utf-8');
soup=BeautifulSoup(content,'html.parser')
ssoup=soup.find("img")
result=str(ssoup)
url=re.search('data-src="(.+?)"',result)
if (url):
upload=requests.post(
baseurl + 'api.php' ,
data={'action':'upload',
'filename':name+'.jpg',
'format':'json',
'token':edit_token,
'url':url.group(1)
},
cookies=edit_cookie,
)
print(upload.text)
###ajouter l'image dans la page
content=''
result=requests.post(baseurl+'api.php?action=query&titles='+name+'&export&exportnowrap')
soup=BeautifulSoup(result.text,'html.parser')
for primitive in soup.findAll("text"):
content+=primitive.string
content='[[Fichier:'+name+'.jpg|right]]\n'+content
payload={'action':'edit',
'assert':'user',
'format':'json',
'utf8':'',
'text':content,
'title':name,
'token':edit_token}
r4=requests.post(baseurl+'api.php',data=payload,cookies=edit_cookie)
else:
print(name+': Picture already online\n****************\n')
if(code.find("Fichier")!=-1):
result=requests.post(baseurl+'api.php?action=query&titles='+name+'&export&exportnowrap')
soup=BeautifulSoup(result.text,'html.parser')
content=''
for primitive in soup.findAll("text"):
content+=primitive.string
xx=content.split("[[Fichier:")
try :
lol=xx[1].split("jpg|right]]")[0]
xx[1]=xx[1].split("jpg|right]]")[1]
except:
lol=xx[1].split("jpg]]")[0]
xx[1]=xx[1].split("jpg]]")[1]
if(xx[0].find('\n')!=-1):
content='[[Fichier:'+lol+'jpg|right]]\n'+xx[0]+'[[Fichier:'.join(xx[1:len(xx)])
print(name+': Picture put on top of page\n****************\n')
payload={'action':'edit',
'assert':'user',
'format':'json',
'utf8':'',
'text':content,
'title':name,
'token':edit_token}
r4=requests.post(baseurl+'api.php',data=payload,cookies=edit_cookie)
IMAGEBOT_v2_namesearch
Recherche non automatisé qui permet de préciser des paramètres de recherche plus spécialisées comme l'ajout du paramètre "place" pour les endroits. Et qui ajoute un paramètre de décision si on souhaite remplacer une image déjà en ligne.
Ou lancement du Bot pour une seule page en utilisant
names=['tous les titres des pages souhaités a illustrer' 'espacés']
prop='' pour name search only
='_'+'additional parameter' pour recherche avec paramètre
rep= True si image peut être mise ajour en ligne
= False pour le première lancement ou une verification du placement sur la page
import re
import urllib2
import requests
import os
from bs4 import BeautifulSoup
user='***'
passw='***'
baseurl='http://wikipast.epfl.ch/wikipast/'
baseur2='https://images.search.yahoo.com/search/images;_ylt=AwrB8pBc0hFZIkIAyZeJzbkF;_ylu=X3oDMTBsZ29xY3ZzBHNlYwNzZWFyY2gEc2xrA2J1dHRvbg--;_ylc=X1MDOTYwNjI4NTcEX3IDMgRhY3RuA2NsawRiY2sDZHBxYWxxbGNoM2s5MiUyNmIlM0QzJTI2cyUzRDFrBGNzcmNwdmlkA2xzbUxMelk1TGpIYzZWWFZXUkhSSWdOck1USTRMZ0FBQUFBd0ZpaFcEZnIDc2ZwBGZyMgNzYS1ncARncHJpZAMzQkZ5V1ZJelI0dUkyUWtoeUx5SWVBBG10ZXN0aWQDbnVsbARuX3N1Z2cDMTAEb3JpZ2luA2ltYWdlcy5zZWFyY2gueWFob28uY29tBHBvcwMwBHBxc3RyAwRwcXN0cmwDBHFzdHJsAzcEcXVlcnkDU2Nod2VpegR0X3N0bXADMTQ5NDM0MDIxMAR2dGVzdGlkA251bGw-?gprid=3BFyWVIzR4uI2QkhyLyIeA&pvid=lsmLLzY5LjHc6VXVWRHRIgNrMTI4LgAAAAAwFihW&p='
#Search Terms (Page Titles)
names=['Constance']
#Kind of page
prop='place'
#replace image yes or no
rep=True
#recherche images creative common & mise sur le serveur
# Login request
payload={'action':'query',
'format':'json',
'utf8':'',
'meta':'tokens',
'type':'login'}
r1=requests.post(baseurl + 'api.php', data=payload)
#login confirm
login_token=r1.json()['query']['tokens']['logintoken']
payload={'action':'login',
'format':'json',
'utf8':'',
'lgname':user,
'lgpassword':passw,
'lgtoken':login_token}
r2=requests.post(baseurl + 'api.php', data=payload, cookies=r1.cookies)
params3='?format=json&action=query&meta=tokens&continue='
r3=requests.get(baseurl + 'api.php' + params3, cookies=r2.cookies)
edit_token=r3.json()['query']['tokens']['csrftoken']
edit_cookie=r2.cookies.copy()
edit_cookie.update(r3.cookies)
for name in names:
result=requests.post(baseurl+'api.php?action=query&titles='+name+'&export&exportnowrap')
soup=BeautifulSoup(result.text, 'html.parser')
code=''
for primitive in soup.findAll("text"):
code+=primitive.string
if ((code.find("Fichier")==-1)or rep): #controle si il y a déja un Fichier et si il faut le remplacer
print('\n****************\n'+'search image for '+name+'_'+prop+'\n****************\n')
search=name+'_'+prop
#recherche image taille M (droits utiliser et distribution NON COMMERCIALE
result=urllib2.urlopen(baseur2+prop.encode('utf-8', 'replace')+'&fr=sfp&fr2=sb-top-images.search.yahoo.com&ei=UTF-8&n=60&x=wrt&imgsz=medium&imgl=fsu')
content=result.read().decode('utf-8');
soup=BeautifulSoup(content,'html.parser')
ssoup=soup.find("img")
result=str(ssoup)
url=re.search('src="(.+?)"',result)
if (url):
if(rep): #mise en ligne d'un fichier existant
upload=requests.post(
baseurl + 'api.php' ,
data={'action':'upload',
'filename':name+'.jpg',
'format':'json',
'token':edit_token,
'url':url.group(1),
'ignorewarnings':True
} ,
cookies=edit_cookie,
)
else: #mise en ligne d'un nouveau fichier
upload=requests.post(
baseurl + 'api.php' ,
data={'action':'upload',
'filename':name+'.jpg',
'format':'json',
'token':edit_token,
'url':url.group(1)
} ,
cookies=edit_cookie,
)
print(upload.text)
###ajouter l'image dans la page
if (rep==0):
content=''
result=requests.post(baseurl+'api.php?action=query&titles='+name+'&export&exportnowrap')
soup=BeautifulSoup(result.text,'html.parser')
for primitive in soup.findAll("text"):
content+=primitive.string
content='[[Fichier:'+name+'.jpg|right]]\n'+content
payload={'action':'edit',
'assert':'user',
'format':'json',
'utf8':'',
'text':content,
'title':name,
'token':edit_token}
r4=requests.post(baseurl+'api.php',data=payload,cookies=edit_cookie)
else:
print(name+': Picture already online\n****************\n')
if(code.find("Fichier")!=-1):
result=requests.post(baseurl+'api.php?action=query&titles='+name+'&export&exportnowrap')
soup=BeautifulSoup(result.text,'html.parser')
content=''
for primitive in soup.findAll("text"):
content+=primitive.string
xx=content.split("[[Fichier:")
try :
lol=xx[1].split("jpg|right]]")[0]
xx[1]=xx[1].split("jpg|right]]")[1]
except:
lol=xx[1].split("jpg]]")[0]
xx[1]=xx[1].split("jpg]]")[1]
if(xx[0].find('\n')!=-1):
content='[[Fichier:'+lol+'jpg|right]]\n'+xx[0]+'[[Fichier:'.join(xx[1:len(xx)])
print(name+': Picture put on top of page\n****************\n')
payload={'action':'edit',
'assert':'user',
'format':'json',
'utf8':'',
'text':content,
'title':name,
'token':edit_token}
r4=requests.post(baseurl+'api.php',data=payload,cookies=edit_cookie)