CurvyBot
Résumés des fonctionnalités
L'objectif de ce bot est de créer pour chaque biographie un graphe avec en abscisse le temps (en années) et en ordonnée le nombre d'articles par année qui traitent du personnage de la biographie. Les événements mentionnés dans la biographie sont clairement indiqués. Le graphe doit donner une idée de la popularité médiatique du personnage au fil du temps, en fonction des événements marquants le concernant.
Description technique
Le bot se base sur les biographies existantes. La page de chaque biographie est analysée pour en extraire le nom du personnage, des mots remarquables qui seront utilisés pour l'évaluation de la performance et les événements biographiques qui seront affichés sur le graphe.
Le nom du personnage est utilisé pour effectuer une requête à la base de données Impresso, qui retourne pour chaque année le nombre d'article comprenant les mots cherchés. Ces données permettent directement de créer un graphe relatif. Chaque point indique le ratio normalisé entre le nombre d'articles total sur l'année et le nombre d'articles concernant les mots-clef. En effet, le nombre d'article total varie fortement selon les années, et un compte absolu ne serait pas représentatif de l'évolution.
Évaluation des performances
Fiabilité
L'usage de mots remarquables permet de générer plusieurs courbes en effectuant une requête plus précise. La comparaison de ces courbes permet d'évaluer leur fiabilité. On effectue notamment une recherche avec le nom complet du personnage, une recherche avec uniquement son nom de famille, et des recherches avec des mots remarquables. Plusieurs techniques d'extraction de mots remarquables sont proposées:
- Extraction des mots à occurrences multiples dans les pages.
- Extraction des fonctions générées par le SPARQLBot dans les mentions.
Initialement, 3 courbes sont calculées.
- La courbe de confiance moyenne est calculée en recherchant les articles où le nom complet du personnage apparaît. C'est la courbe de référence.
- La courbe de confiance basse est calculée en recherchant les articles où seul le nom de famille du personnage apparaît. On s'attend à trouver des pics parasites dans cette courbe. Son but est de représenter au mieux l'amplitude des courbes de confiances plus élevées en minimisant le nombre de faux négatifs.
- La courbe de confiance haute est calculée en recherchant les articles où le nom complet ainsi qu'un mot remarquable apparaissent. On s'attend à ce que certains pics avérés manquent à cette courbe. Son but est de confirmer la présence des pics dans les courbes de confiance plus basses en minimisant le nombre de faux positifs. Cette courbe est la somme des résultats pour le nom complet + un mot remarquable, et son échelle n'est donc pas la même que les deux autres courbes, car certains articles sont comptés plusieurs fois.
Généralement, la correspondance entre la courbe de confiance élevée et la courbe de confiance moyenne est excellente. La courbe de confiance basse est souvent visiblement altérée par des homonymes.
Certains cas spéciaux donnent de mauvais résultats car le nom sélectionné par l'algorithme n'est pas pertinent pour les recherches, comme Otto von Bismarck ou Nicolas II. Ces cas ne sont malheureusement pas rares.
Ce bot est partiellement dépendant du SPARQLBot, qui lui permet d'affiner la sélection de mots remarquables. Toutefois, la présence ou non de mention ne semble pas affecter significativement la performance du bot.
Vitesse
En moyenne, le bot nécessite entre 5 et 10 secondes afin de créer un histogramme et de le téléverser sur wikipast. Un des plus gros problèmes de performance est celui du réseau qui provoque des erreurs après un trop gros nombre de connexions, le transfert des images demandant beaucoup de ressources.
Améliorations possibles
Les critères actuels de recherche occasionnent quelques difficultés. On citera
- Le nom de famille est aussi un prénom courant (e.g. Louise Michel)
- Le personnage est évoqué selon un titre accompagné de son nom de famille (e.g. général von Bismarck)
- Le nom de famille est utilisé pour nommer une invention ou une marque (e.g. Ferrari)
- Le nom de famille a un homographe (e.g. Breton, Lumière)
Le critère de définition d'un mot remarquable pourrait être revu. Actuellement, il s'agit juste d'une borne sur son nombre d'apparitions dans la biographie. Pour permettre une meilleure comparaison entre diverses personnalités il serait peut-être plus juste de choisir un nombre fixe de mots parmi les plus fréquents dans la biographie.
Le critère de recherche par le nom est donc parfois une borne peu, voir pas du tout, précise. On soulignera toutefois qu'elle prouve son efficacité dans une majorité de cas. On pourrait imaginer un premier affinage du critère de confiance bas en regardant, par exemple, si le nom se trouve dans un dictionnaire.
Certains personnages sont très peu mentionnés dans les médias et le graphe pourrait être reconstitué à partir des évènements wikipast (e.g. Yuri Gagarin)
Le format des pages est problématique. On citera
- Le personnage n'a pas de nom de famille (e.g. Nicolas II)
De plus, le bot utilise considère le nom de famille comme étant tout les mots qui suivent le prénom. Il considèrera donc les autres prénoms comme une partie du nom de famille (e.g. Juan Manuel Fangio sera recherché par Manuel Fangio)
Exemple de résultats

Le résultat pour Friedrich Dürrenmatt permet de bien voir le retour en force de son oeuvre au début du 21ème siècle
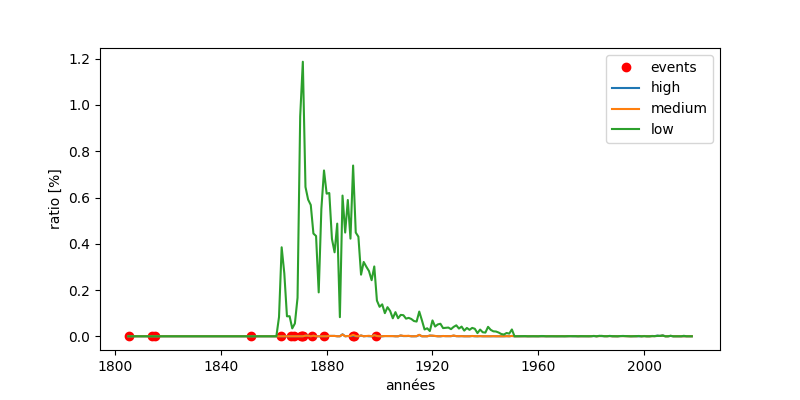
Otto von Bismarck étant souvent mentionné en tant que général von Bismarck la courbe on trouve beaucoup plus de résultats pour "von Bismarck". La courbe low semble toutefois donner un bon résultat par rapport à la vie de Bismarck et sa popularité décroît après sa mort.


Code
Nous utilisons les imports et constantes suivantes
import requests
import matplotlib.pyplot as pp
import numpy as np
from urllib.request import urlopen as urlopen
from bs4 import BeautifulSoup
from matplotlib.pyplot import figure
from matplotlib.dates import (YEARLY, DateFormatter, rrulewrapper, RRuleLocator, drange)
from datetime import datetime as dt
import nbimporter
from in_progress import *
from contextlib import closing
import time
FIRST_EVENT_SHIFT = 20 #if no birthday is found in wikipast's events then the originating event for impresso is the first one FIRST_EVENT_SHIFT years earlier
PAUSE_TIME = 180 #on timeout wait PAUSE_TIME seconds
GENERATED_FILENAME = 'CurvyBot_output.png'
user = #Bot credentials
passw = #Bot credentials
baseurl='http://wikipast.epfl.ch/wikipast/'
impresso_token = #Impresso connection token
payload={'action':'query','format':'json','utf8':'','meta':'tokens','type':'login'}
r1=requests.post(baseurl + 'api.php', data=payload)
login_token=r1.json()['query']['tokens']['logintoken']
payload={'action':'login','format':'json','utf8':'','lgname':user,'lgpassword':passw,'lgtoken':login_token}
r2=requests.post(baseurl + 'api.php', data=payload, cookies=r1.cookies)
Une boucle principale itère sur toute les biographies
with closing(urlopen("http://wikipast.epfl.ch/wikipast/index.php/Biographies")) as html_biographies:
soup = BeautifulSoup(html_biographies, 'html.parser')
hrefs = []
for table in soup.findAll('table'):
for a in table.findAll('a'):
if a.has_attr('href'):
hrefs.append('http://wikipast.epfl.ch' + a.get('href'))
"""for each biography creates a new section with an histogram
if the section doesn't exist and reuploads the histogram otherwise"""
times = {}
for i, bio in enumerate(hrefs):
print(bio)
timeout = True
while timeout:
try:
start = dt.now()
end = start
bns = bio_needs_section(bio)
fname, title = None, None
if(bns):
fname, title = create_histogram(bio)
end = dt.now()
add_histogram(fname, title, bns)
timeout = False
print('graph realisation and insertion took', end - start)
times[bio] = end - start
except TimeoutError:
print("Timeout")
time.sleep(PAUSE_TIME)
print(times)
Pour chaque biographie un graphe est crée et mis sur la biographie wikipast. La création du graphe est faire avec le code suivant
def generate_plot(event_dates, birthday, bio):
pp.figure(figsize=(8.0,4.0),dpi=100)
plots = ask_dates(birthday, bio)
labels = ['high', 'medium', 'low']
events = pp.plot_date(event_dates, np.zeros(len(event_dates)), fmt='ro', label='events')
for i, p in enumerate(plots):
if i < len(labels):
pp.plot_date(p[0], p[1], fmt='-', label=labels[i])
else:
pp.plot_date(p[0], p[1], fmt='-')
ax = pp.gca()
ax.set_xlabel('années')
ax.set_ylabel('ratio [%]')
pp.legend()
pp.savefig(GENERATED_FILENAME, facecolor='w', edgecolor='k',
orientation='portrait', format='PNG')
pp.show()
return GENERATED_FILENAME
def create_histogram(bio):
event_dates, birthday, title = wikipast_events(bio)
fname = generate_plot(event_dates, birthday, bio)
return fname, title
Afin de récupèrer les différentes valeurs à dessiner nous utilisons
def ask_dates(birthday, bio):
dict_list = bioToDictionnaries(bio, birthday, impresso_token)
plots = [dictionnary_to_plot(d) for d in dict_list]
return plots
def wikipast_events(bio):
event_dates = []
birthday = None
title = ""
with closing(urlopen(bio)) as html_character:
character = BeautifulSoup(html_character, 'html.parser')
title = character.find("h1").find(text=True)
for megaEvent in character.find_all(["h2", "ul"]):
if megaEvent.name == "h2" and megaEvent.text != "Biographie":
break
elif megaEvent.name == "ul":
for event in megaEvent.findAll('li'):
event_date = event.find('a').get('title')
formatted = format_date(event_date)
if formatted:
event_dates.append(formatted)
for text in event.findAll(text=True):
if 'naissance' in text.lower() and not birthday:
birthday = formatted
if(not birthday):
if event_dates:
first_event = event_dates[0]
birthday = dt(first_event.year - FIRST_EVENT_SHIFT, first_event.month, first_event.day)
else:
birthday = dt.min
return event_dates, birthday, title
Afin de formatter les dates de wikipast et de convertir les résultats d'Impresso vers une version facilement dessinable nous utilisons les fonctions utilitaires suivantes
def format_date(date):
date_parsed = date.split(' ')[0].split('.')
if(not date_parsed[0].isdigit()):
return None
completion_date = ['01','01']
date_corrected = [date_parsed[0]]
for i, parsed in enumerate(date_parsed[1:]):
if parsed.isdigit():
date_corrected.append(parsed)
else:
date_corrected.append(completion_date[i-1])
date_corrected = date_corrected + completion_date[len(date_parsed)-1:2]
formatted = None
try:
formatted = dt(int(date_corrected[0]), int(date_corrected[1]), int(date_corrected[2]))
except ValueError as err:
print("DATE FORMAT ERROR")
return formatted
def dictionnary_to_plot(d):
d = d.items()
d = sorted(d, key=lambda x: x[0])
keys_dt = [dt(y[0],1,1) for y in d]
vals = [r[1] for r in d]
return (keys_dt, vals)